How we optimised for iteration speed with data build tool (dbt)



Last editedNov 20202 min read
The Business Intelligence team enables data-driven decision making across GoCardless. We migrated some 26,000 lines of SQL into dbt to improve their speed of iteration and shaved over 2 hours off our ELT pipeline. Here's how.
GoCardless is growing fast. As we grow in size, so too does the number of data-related questions. And, as our teams mature, those questions become more sophisticated. It's our role in the Business Intelligence (BI) team to ensure our BI scales alongside the business.
Internally we’ve seen our technical debt compound, which slows us down and increases the complexity of our work. As the interest on the debt accrues, it becomes harder to pay and - if left unchecked - could eventually erode confidence in our data.
For us, these two challenges are a symptom of a broader problem: a slow speed of iteration. If we improve our speed of iteration, we can better meet demand across the business and improve confidence in our data.
The Airflow bottleneck
At the heart of our data infrastructure is Apache Airflow. We use Airflow for a variety of tasks, from triggering Dataflow jobs in GCP to running our SQL-based transformation pipelines. Whilst Airflow is a vital part of our infrastructure, it constrains our ability to iterate our SQL-based pipelines due to its slow DAG execution and development workflow.
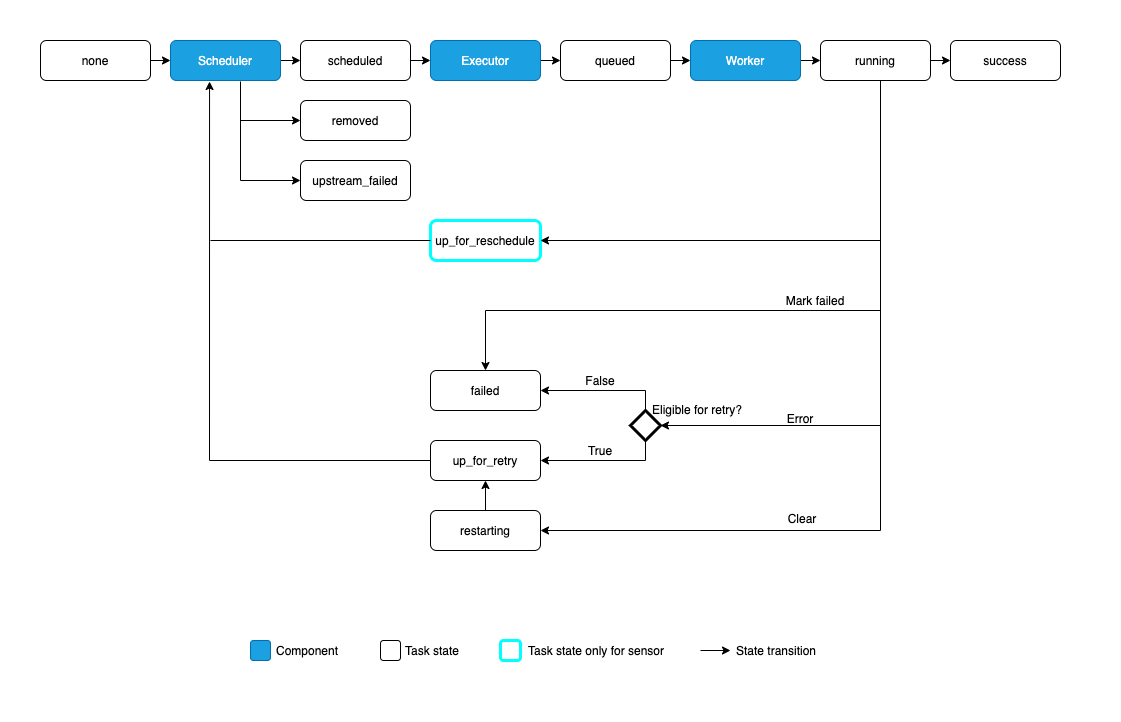
In terms of DAG execution, the Airflow scheduler monitors task statuses at regular intervals to figure out which tasks can be run. When a task's dependencies are met, the task is sent to a queue and eventually run by a worker resource. Throughout the entire process the scheduler regularly checks on the task status. Whilst Airflow is versatile, this process is slow at running hundreds of small, short-lived tasks like creating views in a database.
Before using dbt (data build tool), our data warehouse development was tightly coupled with Airflow. To test code written for Airflow you need to run Airflow, and for SQL-based pipelines this seemed like overkill to us.
Before moving to dbt, we provisioned multiple test environments for development. The trouble is, as teams grow you need more and more test environments to avoid developer queues and idle time. Couple this with a slow running DAG and it’s clear that our development process wasn’t conducive to agile data warehouse development. Ultimately, this constrained our speed of iteration and ability to support the business.



The life of an Airflow Task (source)
The advantages of dbt
dbt is a command line tool for building SQL-based transformation pipelines. dbt is lightweight and is able to plan and execute pipelines for us. It's an open source tool with batteries included: a built-in test framework and a static site generator based to help document your pipeline.
Before migrating to dbt, we compared our existing setup that relied on Airflow’s BigQuery operators to dbt. Our original setup took over 30 minutes to construct 100+ views (due to Airflow's internal processes). In dbt, the same set of operations took 2 minutes - a massive performance gain.



dbt can also be run locally with few dependencies. This enabled us to decouple data warehouse development from Airflow and further improve our speed of iteration.
Using dbt and Airflow together
At GoCardless we use Airflow and dbt together. The pairing enables us to leverage the best of both worlds. We gain dbt’s great development workflow and fast DAG execution, as well as maintain a tight integration with other jobs running in Airflow.
You can see how we run them together here.



Across a two week period, we migrated some 26,000 lines of SQL into dbt with zero interruption to the business. The entire team took part in the migration. We chose to include the whole team as an opportunity to educate, and ensure every member was comfortable and effective with dbt.
After the migration, we had an entire team confident in the use of dbt. Thanks to some clever migration choices, we delivered zero downtime to our Looker users.
The results in numbers
In production, our transformation pipeline is 7x faster (down from 3 hours to just 25 minutes). Data warehouse development is now largely decoupled from Airflow, providing another boost to our speed. And that’s not to mention we’ve improved our test coverage by 5x and now use dbt’s static site generator to share knowledge across the team.
We are now able to meet a growing demand for insight so we can better support the business as it grows. We can do this whilst painlessly paying down our technical debts to improve confidence in our data, all thanks to a vast improvement in our speed of iteration.



{kind=link}