Having Fun with Markdown and Remark






Last editedAug 2020
I went down a rabbit hole of learning how to parse Markdown to add custom syntax to it. I had to go through a few projects and learn how to work with a new type of abstract syntax tree (AST). Previously, my experience with ASTs was limited to writing codemods using jscodeshift. In the end, it turned out to be a worthwhile investment of time! In this post, I'll go over what I learned using a problem I wanted to solve.
The problem
I wanted to introduce a new syntax to Markdown that lets authors add stylised subtitles to their documents. Using smaller headings to give the appearance of subtitles is not a great solution. It is not considered semantic HTML and it also hurts accessibility because it introduces extra, unintended headings to the document's accessibility tree.
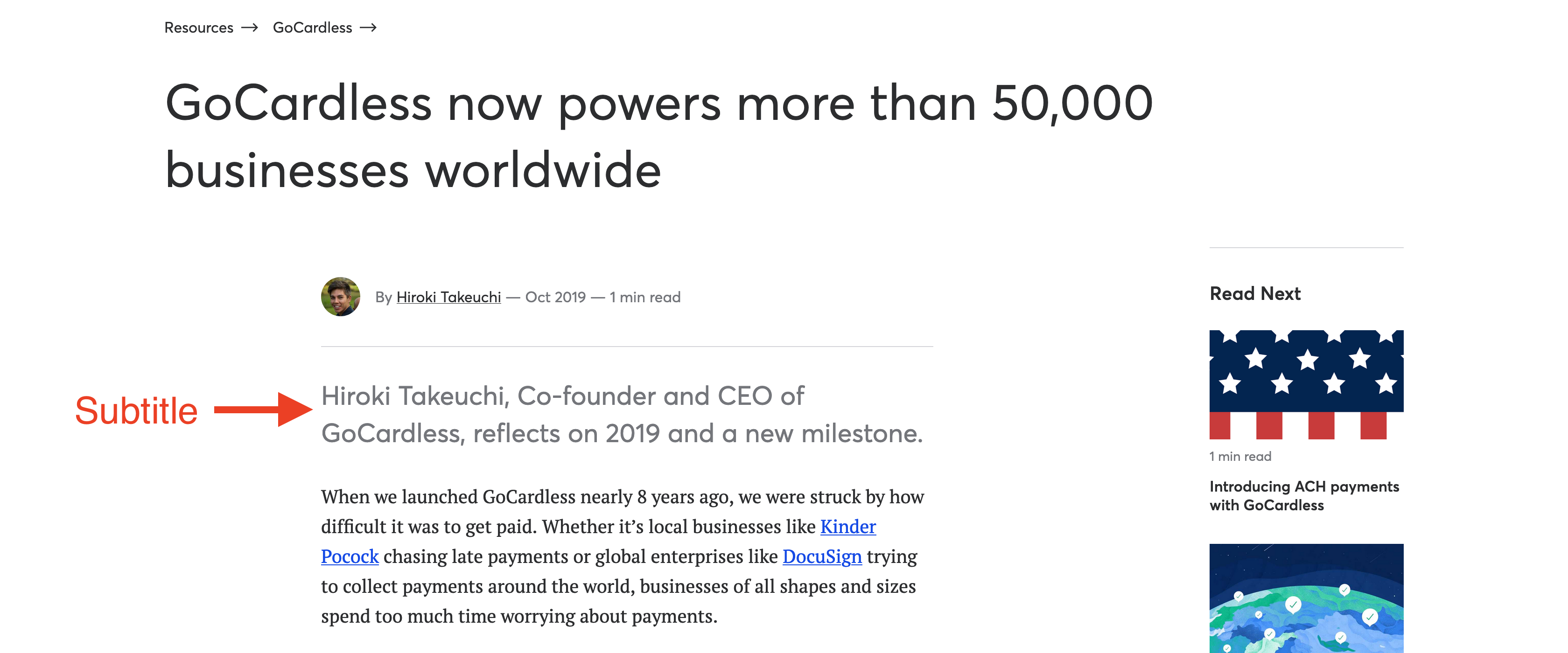
What I wanted was a new syntax that looked like this:
# I am a level 1 heading
#- I am a level 1 subtitle
##- I am a level 2 subtitle
######- Up to six levels are supported corresponding to heading levelsWhen rendered to HTML these should come out as:
<h1>I am a level 1 heading</h1>
<p class="subtitle subtitle--1">I am a level 1 subtitle</p>
<p class="subtitle subtitle--2">I am a level 2 subtitle</p>
<p class="subtitle subtitle--6">
Up to six levels are supported corresponding to heading levels
</p>The ecosystem
Currently, the best tools to use for this task exist in the node.js ecosystem. These are:
- unified - an interface for parsing, inspecting, transforming, and serializing content through syntax trees
- remark - a Markdown processor powered by plugins part of the unified collective
- mdast - a specification for representing Markdown in a syntax tree (see this example)
- hast - a specification for representing HTML (and embedded SVG or MathML) as an abstract syntax tree. You can use rehype to parse html text as hast.
- unist - is a specification for syntax trees. mdast and hast are unist-compliant syntax trees.
What do these tools look like in practice? The following code gives an idea of what a processing pipeline looks like:
// our Markdown parser that spits out mdast
const remark = require("remark");
// an mdast to html serializer
const html = require("remark-html");
// the plugin we'll write
const subtitlePlugin = require("./remark-subtitles");
const text = `
# Hello
###- How are __you__?
Great!`;
remark()
.use(subtitlePlugin)
.use(html)
.process(text /* Markdown in */, function (err, file) {
if (err) throw err;
console.log(String(file)); /* HTML out */
});
});The solution
Starting from this, we can now write our plugin. The following snippet shows the plugin code with comments annotating the interesting parts.
// These `unist-util-*` utilities are super useful when working with unist
// syntax trees
const is = require("unist-util-is");
const visit = require("unist-util-visit");
// We're going to need this to convert some mdast nodes to hast nodes later on
const mdastToHast = require("mdast-util-to-hast");
// Our plugin's constructor function. This would receive configuration options.
module.exports = function subtitlePlugin() {
// Plugins need to return a transform function that takes a unified compatable
// AST and manipulate or walk it.
return async function transform(tree) {
// Go through the Markdown document (in mdast form) and call my callback
// whenever you see paragraph nodes.
visit(tree, "paragraph", (paragraphNode) => {
const { children } = paragraphNode;
// Get the first child node under the paragraph and make sure it's a text
// node. If it's not, skip processing this paragraph node.
const textNode = children && children[0];
if (!is(textNode, "text")) {
return;
}
// Does this text node start with a sequence of hash ('#') signs followed
// by a dash ('-')?
const text =
typeof textNode.value === "string" ? textNode.value.trimLeft() : "";
const re = /^(#{1,6})-\s+/;
const matches = text.match(re);
if (typeof text === "string" && !matches) {
return;
}
// If it did let's count the number of '#'s as that will be our subtitle
// depth
const depth = matches[1].length;
// Once we have what we need, let's make a copy of this text node without
// the leading subtitle syntax.
// i.e. '##- hello world' becomes 'hello world'
const newValue = text.replace(re, "");
// We can now attach some metadata to an mdast node. If the node is being
// serialized to html by a hast-compatible library, it will know to use
// these overrides instead of the default behaviour of rendering a plain
// <p> tag.
paragraphNode.data = {
// we could use a different html tag but "p" is semantically correct for
// the subtitle
hName: "p",
// The <p> tag will have the following attributes added to it.
// Note that we need to use "className" for the html "class" attribute.
hProperties: {
className: `subtitle subtitle--${depth}`,
"data-remark-subtype": "subtitle",
"data-subtitle": depth,
},
// When we are passing custom children, it is our responsibility to make
// sure they are in hast format instead of mdast. We use the library,
// mdast-util-to-hast, to do this conversion.
hChildren: [
// We pass in a modified text node without the leading subtitle
// characters
{
...textNode,
value: newValue,
},
// Then we pass in the rest of the children under this paragraph node
...children.slice(1),
].map(mdastToHast), // Finally convert it all to hast
};
});
};
};If you'd like to play with a runnable version of this code check out this runkit demo.
Wrap up: Why is this cool?
Beyond adding new syntax, being able to analyse Markdown unlocks a lot of automation and authoring enhancements. Here are some ideas of where you can go with this:
- Write your incident response documents in Markdown and use
- []to create action items. Now, you can write a parser and pipeline that runs in CI to create tickets for these and update the document with links to them. - Use remark to lint Markdown documents for things like too many spaces (e.g. extra space)
- Use remark to take links to an excalidraw diagram and embed a preview on hover feature
Check out these awesome remark plugins if you're looking for inspiration. I hope this helps you get started!


